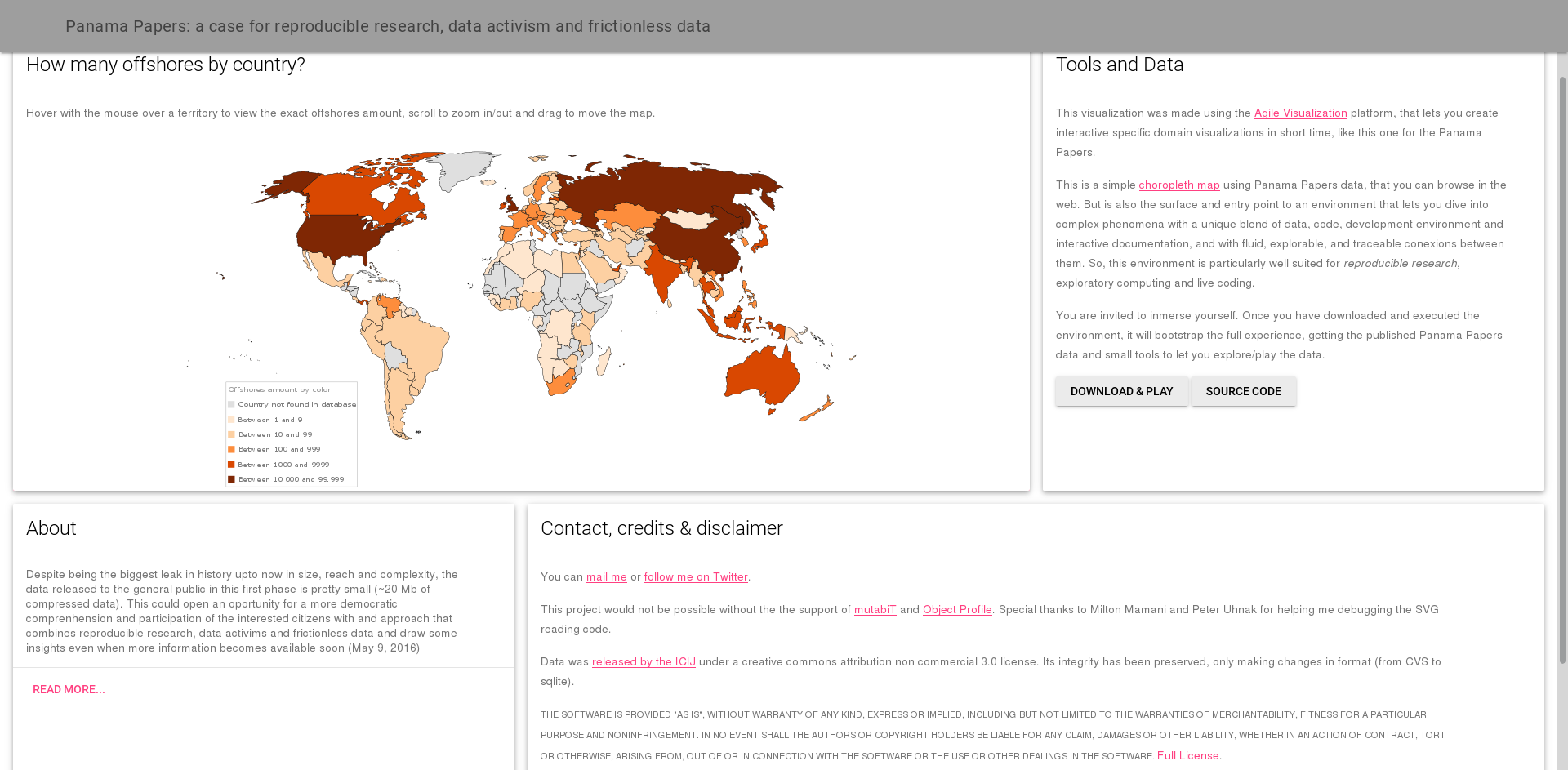
Hi,
Tomorrow, the second data batch of the Panama Papers will be released, so I would like to share this two links entitled: Panama Papers: a case for reproducible research, data activism and frictionless data
That advocate for a more plural participation complex data phenomena like this one, proposing practices with the released data and prototyping a portable, simple and affordable data continuum environment.
This is related with several topics addressed in this community, like frictionless data and the treads about Best examples of data journalism and computational journalism projects around tax? or the Paper: “Democratising the Data Revolution”, with a strong emphasis on citizen practices and technologies.
Here are the screenshots:
And, of course, I tweeted about it, with cc to @OKFN:
#PanamaPapers: a case for #ReproducibleResearch, #DataActivism & #FrictionlessData https://t.co/kD00BRvsMd @OKFN pic.twitter.com/wrfX5pCSRO
— Offray Vladimir Luna (@offrayLC) 7 de mayo de 2016
There will be some changes in the downloadable soon, but a working prototype has been released (see project minisite above).
Any comments or suggestions are welcomed.
Cheers,
Offray
Ps: I would like to add a new tag about data-activism but seems I have not the proper permissions.
Just some minutes left and we will get access to more than 200,000 offshore entities that are part of the Panama Papers investigation.
Stay Updated: https://offshoreleaks.icij.org/
Regards,
Thanks for commenting Nikesh. As I said in the long blog entry:
The first batch with 278.693 records was pretty manageable with this technology,
the second batch promise to add 200.000 records more, so seems that this approach
will be applicable. But still, there is work do be done on small and large scale.
and
Panama Papers are an example of what can be done with tools like the ones described here and is sure that this will be added as a important example to our future data week workshops, so other citizens, studens and/or journalists can learn from it and extend it. In such workshops we could improve and stabilize the code and keep a look to future releases of the data to see how easy is to interact with it and if some of this ideas and contributions or better ones are in some way incorporated there. I hope this inspire others for similar approaches on making partipatory reproducible research or to help me with this particular approach and problem.
so, surely we will keep a look at the upcoming release and see if there the changes, besides data size and amount of new records, which are already pretty important, go in the direction of empowering more people to bridge the gap between data and argumentation.
Cheers,
Hi, I have updated the blog post with the latest release of the data by the ICIJ. Soon I hope to publish the complete integrated software artifacts (fighting right now with some GUI glitches). Here it is:
Cheers,
Offray