Hi,
We’re going to make our 7th edition of the Data Week (Spanish) hackathon/workshop, where we attempt a critical code+data literacy and visualization approach. It will be, as usual, an intensive learning experience, composed of two sessions from Thursday to Saturday, from 2:30 pm to 8:30 pm (Oct 27-29 and Nov 4-6). This will be an intermediate level, intended for participants of previous editions.
Today I finished the reading of Feminist Data Visualization by Catherine D’Ignazio and Lauren F. Klein and is nice to see several alignments from this practices from the South, that we’re doing in our hackerspace, and what they’re describing in their paper.
I will underline some of the aspects that try implement such critical approach:
- Is a workshop, because is oriented towards learning by doing in a guided fashion.
- Is a hackathon because is oriented towards prototyping and open problems. But for us hackathons are bridges between the past and the future of a community, instead of the volatile, “fashionist” popular version of today’s hackathon.
- Our tool blends/blurs code, document, data, query and visuals, but it is self contained and fits in “everyone’s pocket” (see the Panama Papers example), which contrasts sharply with exclusionary cloud + big data + connected always discourses, where infrastructure can be owned only by the ones with “deep pockets”. This blurring of the binary (author/lector, developer/user, document/data, app/IDE) and deconstruction of hierarchy is aligned with the ones in the Feminist Data Visualization approach mentioned above.
- Our workshops deal with critical data and problems, instead of the “Hello world” approach to tech learning and is building a diverse community.
- The source code and history of all digital artifacts can be shared openly, to improve the traceability of data and data derived arguments.
- Open web, open standards and open tools are the core of our workflow with data+code from collecting to publishing.
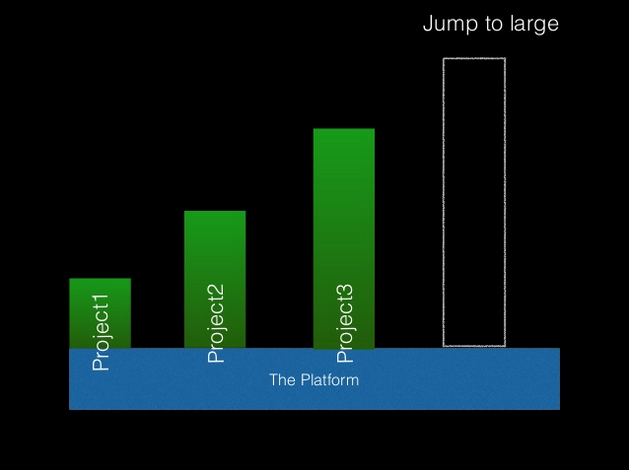
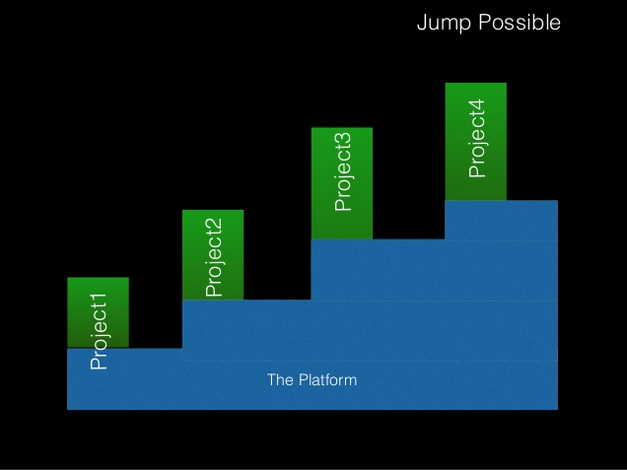
- We try to create local capacity and empower a local community, tackling an advanced version of the same problem, in each edition, by putting knowledge from previous editions into the infrastructure, so learners can “jump” into complex stages of the problem without a lot of cognitive burden. The talk Nomads don’t build cathedrals [1],[2],[3] from Markus Denker, is aligned with this idea. These tree, slides illustrate the approach:

 ^Up |
Making jumps possible in complex projects by modifying the underlying platform/infrastructure.
(Click on each imagen to enlarge).
^Up |
Making jumps possible in complex projects by modifying the underlying platform/infrastructure.
(Click on each imagen to enlarge).
I have updated the memories of previous editions as I said in my last announcement and this edition we’re going to focus on artifacts for publishing the twitter data selfies. So if things advance at good pace, I will share the links for our data selfies galleries here.
Cheers,
Offray
PS: I tried to use HTML embedded tags to make images smaller, but seems that discourse doesn’t allow this.