I’m working on updating OSEP04 right now based on the recent work I’ve done developing a command line interface to load Open Spending Data Packages to flat file storage like S3.
This work raised various questions and points to consider for Open Spending Data Package, which is partly reflected in Rufus’ post above.
I want to try and address the issues to solve as I see them here, partly as a thinking out loud exercise to make a pull request on OSEP04.
I also want to make some points more explicit in regards to Tabular Data Package and Budget Data Package, because I’m sure many in the Open Spending community are not familiar with these specifications, yet the whole dialog here does assume some level of understanding as to what they are.
Background: Tabular Data Package and Budget Data Package
The “Data Package” specifications are a family of formats for standardised publishing of data.
The base Data Package specification is here.
There is a concept of “profiles” in Data Packages. These extend the spec towards more specific application.
Tabular Data Package describes a publishing standard specifically for tabular data (e.g.: CSV).
Budget Data Package is a profile that extends Tabular Data Package to describe a publishing standard for both transactional and aggregate fiscal data.
Why Open Spending Data Package?
We have existing specs for publishing tabular data, and for budgetary data. A long term goal is that Open Spending will support Budget Data Package as its publishing format. So why do we need Open Spending Data Package?
There are a few reasons, some highlighted above by Rufus. I’ll try to expand here.
- Allow the Open Spending data modelling requirements to move quickly based on user need. An Open Spending Data Package allows us to implement changes quickly, whereas Budget Data Package has more stakeholders and a longer process for introducing change.
- Budget Data Package currently
REQUIRES some data fields that are extremely useful (cofog, gfsmRevenue) but that are difficult to enforce on all data uploaded to Open Spending.
- Open Spending services that do their work by getting raw data from the flat file storage may need to be able to rely on conventions that are specific to the implementation of Open Spending, and there needs to be a way to specify these conventions.
What makes an Open Spending Data Package
Above I’ve tried to provide some context. Now, what exactly makes an Open Spending data package?
First, the easy stuff:
- The datapackage.json descriptor has the same property requirements as Budget Data Package, and additionally must have an
openspending property, which is a hash.
- The
openspending HASH requires:
openspending.owner: the username of the person or organization that is publishing this data on Open Spendingopenspending.mapping: A HASH that provides a mapping of fields in the data of each resource in the data package to fields that Open Spending acknowledges. Each key is the name of a field in Open Spending, and the value is the name of the field in the data resource.
The more difficult issues are around a data packages resources.
We know that we want any resource with spend data in it to have at least the following metadata:
- currency
- granularity (aggregate or transactional)
- fiscalYear
And, the data must have an id and amount field, but these may be named differently if mapped as such in openspending.mapping.
All metadata from Budget Data Package is up for inclusion and we need to consider what each data point requires from the Open Spending user.
Problems to solve
Now with a wider context of what we have and why, here are some critical problem to solve as I see them.
Resource consistency inside a data package
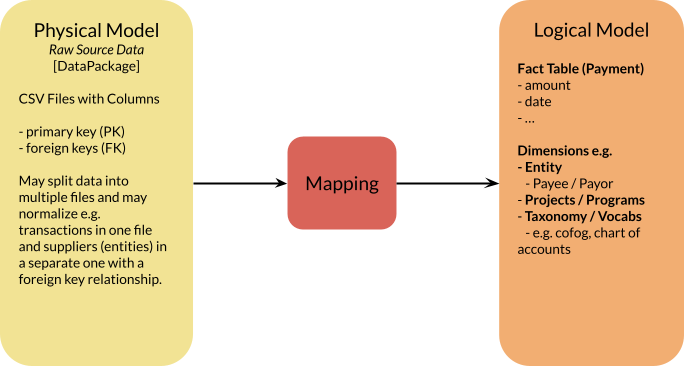
Specific Data Package Profiles, like Budget Data Package, achieve specificity by putting metadata on resource objects. On an abstract level, this makes sense, but in our practical use case here, less so in my opinion. If we consider the design principle that Rufus states above:
OpenSpending data packages should allow for both denormed and normalized data.
denormed data presents no real challenge: every line of data has every thing it needs, and we can imagine therefore that each resource in a data package is equivalent, and conforms to a Profile.
If we consider normalized data, the situation is different. I gave an example here where normalising would prevent huge amounts of data duplication in a spend dataset.
Normalized data presents a challenge for the resource-based meta data model, as, if we want to package normalized data in a single datapackage, well will by definition have resources that have different metadata and data models.
So, to deal with that, one of these two strategies for packaging data are possible:
- Open Spending Data Packages can have different “types” of resources, where only some of them (at least one) need to have spend data (this is a significant divergence from Budget Data Package, which expects all resources to be budget data)
- Use multiple data packages to describe an Open Spending Data Entity
It could be that both strategies for packaging data need to be supported…
Spend data status and type
In Budget Data Package, status provides a way to track different states of spend data. e.g.: for budgets: proposed, executed. There, a single Data Package would have multiple resources, with each resource being a different state of the “same” data.
Rufus raised points above around enforcing different “statuses” as different data packages. When thinking about this, especially in relation to the above point on normalized data, I’m not sure that different data packages is the right solution for that.
Rather, it seems that Open Spending could also enforce the convention of having different states in the same Data Package (as per Budget Data Package), and the logic of aggregation, and analytical modelling in general is for the system to work out based on presence of status, type and other fields?
For reference, here is a somewhat related thread between myself and Tryggvi on status and type in Budget Data Package.
In closing
I think if we can clarify the issues around “Resource consistency inside a data package”, then we can better define what the possible payloads are in an Open Spending Data Package, and from there, drill down and clarify the finer points of the structure(s) of an Open Spending Data Package.