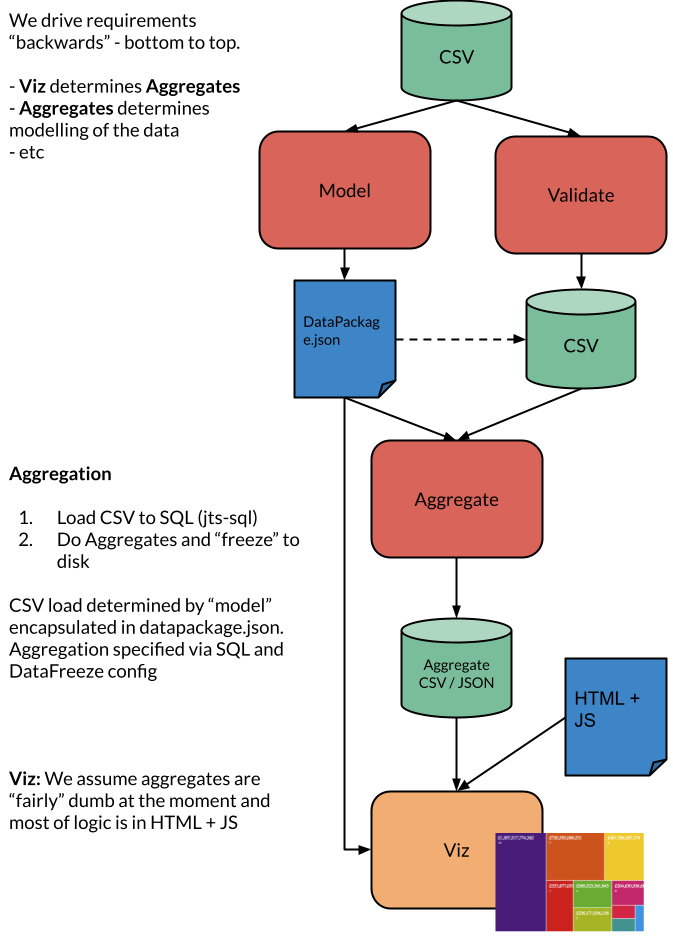
This is topic and diagram is about detailing and discussing the MVP for OpenSpending Next focused on the key steps:
CSV → Data Package → Aggregate → Visualization
This is topic and diagram is about detailing and discussing the MVP for OpenSpending Next focused on the key steps:
CSV → Data Package → Aggregate → Visualization
OK, in the ongoing trialing and thinking through of this workflow after the first experiment, I’ve come up with the following. Excuse the brain dump ![]() .
.
The visualization code needs one, and likely only one, currency for visualization purposes and it needs a single column of amounts (the ‘measure’). These are stored together in an entry in the “measures” object of the current OpenSpending Data Package draft, so that’s good and probably means the visualization code needs to read the datapackage.json. But a single datapackage can have multiple measures, so how should it choose? Just the first?
The visualization code also needs to know where the Aggregate CSV/JSON lives. The obvious place to pull this from would be the aggregates.json file we’re working off currently, but again, how to specify which one?
Along the same lines: the resources object specifies possibly multiple CSVs: how should the aggregation code determine which resource to aggregate on?
Lastly (and I’m mainly thinking out loud here) the SQL statements in the aggregates.json should reflect the mapped the dimensions and measures specified in the datapackage.json (currently, they refer directly to the original CSV columns). So the aggregation code (somewhere between CSV read and jts-sql load), should store the logical columns as fields in the SQL. That seems right, I think. But then the user must use the logical model to generate her aggregation specification. Is that good?
[
{
"columns": ["func1"],
"year": "2006",
"aggregate": "approved",
"where": "transfer = 'Excluding transfers' AND Econ_func = 'Function'",
"file": "by-func1-2006",
"format": "csv"
}
]
In the recent tech hangout, there was much concern over building a simple aggregation spec that used raw SQL to define aggregates. I was also concerned with some of the redundancy inherent in this approach (e.g. “SELECT a,b,c … GROUP BY a,b,c”). In trying to build an script that imports fully normalized datapackages and runs aggregates on the data, I, of course, ran into the problem of needing to join lots of tables.
It turns out that when using SQLAlchemy, it is easier to use a more structured query specification to define these aggregates while also eliminating the redundant GROUP BYs. The above is what I came up with while working on a particular dataset that happened to have a year column and needed special conditions (e.g. “transfer = ‘Excluding transfers’ AND Econ_func = ‘Function’”) to generate a coherent aggregate.
What do you think? Should the “aggregate” column be renamed? How should I handle specific, uncommon conditions without creating a brand new Query Language?
Another thought: maybe aggregates.json could do with some further metadata pointing to the source datapackage? This will allow the front-end code to read aggregates.json, and by extension read datapackage.json to learn about currency, etc. while drawing the visualization.
/aggregates.json
{
datapackage: "https://raw.githubusercontent.com/os-data/boost-armenia/master/datapackage.json",
aggregates: [
{...}
]
}
Hey @danfowler I’m not sure what the best approach is, and we can talk on it some more. What I wanted to flag now is that we use sequelize.js in some of our projects, which is an ORM for Node.js.
The useful thing here is that they have a json-compatible query interface which we could liberally borrow from if this is the direction you want to go in. This has the benefit of not explicitly being tied to SQL in terms of the query interface.
There may be other/better query languages we could repurpose here. Have to look into it further.
Thanks a lot for the sequelize suggestion. An example of the basic aggregate query we’re looking for would look like this:
attributes: ['func1','func2','func3',[Sequelize.fn('SUM', Sequelize.col('foo_table.approved')), 'amount']],
group: ['func1','func2','func3'],
where: {
year: "2006",
transfer: "Excluding transfers",
Econ_func: "Function"
}
For our purposes we could probably simplify this to something like below, determining the aggregate column via the datapackage.json (first key in mapping.measures?):
columns: ['func1','func2','func3'],
where: {
year: "2006",
transfer: "Excluding transfers",
Econ_func: "Function"
}
path: "{computed/}func1-func2-func3-2006.csv"