We, at Queensland University of Technology, have built a data publishing platform using CKAN. Its purpose is to provide a platform to researchers to publish their data either as standalone sets or as supplementary documents for a research publication.
We did encounter some questions that we needed to address on the business practice/business logic level. Namely, what do we do about data that are subject to embargo conditions? what do we do about data that are not quite ready for consumption by the general public (working data)? what do we do about data who’s authors do not wish to share publicly (e.g. pre-journal publication)?
In all of these cases, we would like to provide an opportunity to publicise the existence of the data sets without necessarily publishing them. CKAN’s public/private settings for publishing data sets is not suitable. So we have created a new setting that exposes the metadata but restricts download to authorised users.
Arguably, this is a step back from the open mandate since some data sets are no longer accessible publicly (and anonymously). But the alternative is that we do not put these data sets on CKAN at all. This is also the question of how sustainable is our customisation of CKAN if it is not picked up by the community and remains “niche”.
The other points you raise are, in opinion, related to:
A/ how how should original (mother) data sets and derivative (daughter) data sets be connected?
B/ where is the information that allows us to derive daughter data sets from mother data sets (instructions/code/rationale) to enable reproducibility?
C/ how should this information be presented so that can be subject to public scrutiny (verifiability)?
D/ how to connect original data sets with replicated data sets? (i.e. data sets that used the same methods to be collected/derived but rely on different source material.)
CKAN on its own is not enough. Linking it to scientific workflow software would be a good step towards answering these questions. In my (limited) experience, scientific workflow software are highly variable in quality and application. Some of them are very specific to a particular scientific domain or type of application. Others can be cumbersome or not very user-friendly. On the other extreme are generic tools that require programming experience such as R or Matlab (or Python or whatever.)
But still, in my opinion, it is probably on the level of human practice that processes need to be developed. Ultimately, if researchers do the right thing and provide the information needed, it does not matter what tools we choose. Unfortunately, this requires a level of education and training that we have not been able to provide so far.
Thanks Marco - for the work to include restricted datasets was this implemented as an extension? We have done the same work at Link Digital for data.brisbane.qld.gov.au but I suspect haven’t released the code as yet. We should compare approaches and get the code out for others to share
Regarding scientific workflow software this is a good point. I mentioned the idea of a ‘resource containers’ model for CKAN in the dev list and would like to flesh out the use case more before suggesting it again. However, CKAN already has something like this in practice with data store and file store if you consider them as ‘resource’ extensions. I think building out a bigger set of these would be very helpful.
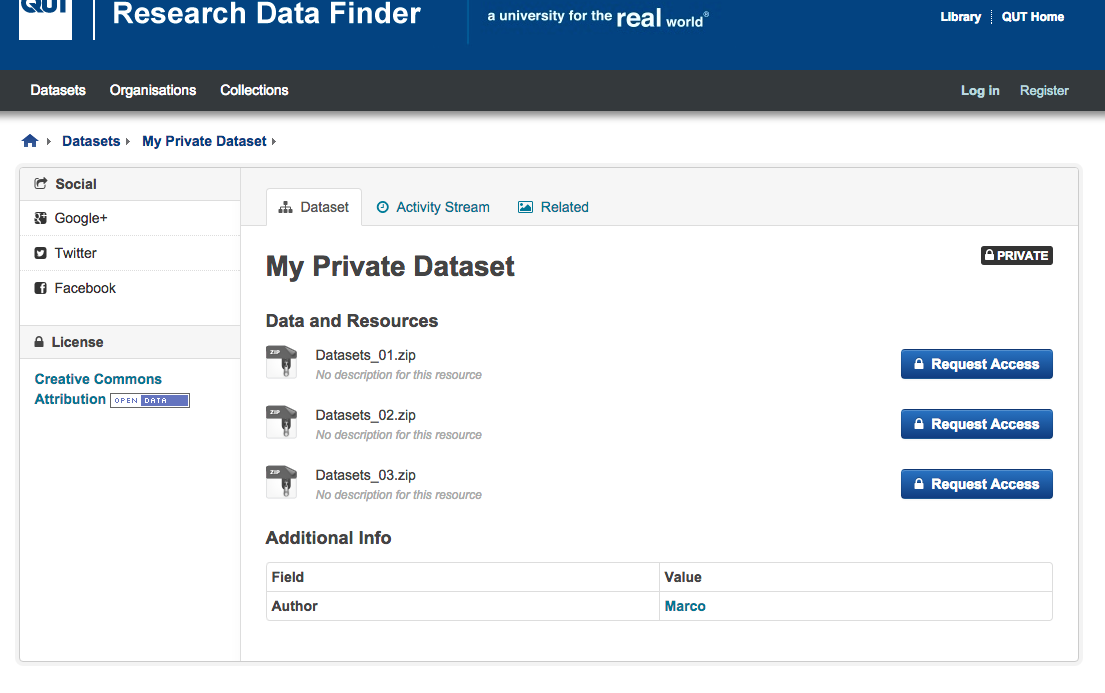
We have not released our repository publicly yet. But this is a screenshot of how it looks like. Clicking on “Request access” takes you to a form which, once submitted, an email is sent to the author.
I am not sure how we implemented this change. I need to consult with my colleagues. I think it was done on the presentation layer. However, I am ambivalent about this feature for the reasons I outlined above. I take my lead from Bristol Uni who have a clearly described mandate that does not require that feature (Welcome - data.bris bottom of the first paragraph)
Neat - one thing to check would be the API request method. With the approach we used you can protect such assets by requiring a user’s API key to be sent with the request. I suspect you might have a custom response to again contact the dataset owner. I’ll check into our side and see if we can get the code released soon.
Hi Marco,
We did some experimentation at the beginning of the year with child resources on CKAN. It just involved adding a ‘parent’ field in the extras of the resource. It looked something like this:
A display like this could be useful when figures are derived from data (though it has its limits considering we often have data+code=figure) or maybe especially when data is refined from other data.
The idea could probably be extended to other data handling languages like R and Python. Whether CKAN is the right home for all of this is the other question, but I think there’s a role for this purely for transparency reasons. I love the idea of the “paper trail”.
This is nice… we are looking at a resource view for zipped files right now. Where those files contain actual resources (data) we’re looking at presenting them in the same way as the resources listing.
But, early stages right now. Just a bit of work to do and the code for the extension can be released for others to improve on as required I’ve been thinking about the use cases for the API requests for resources contained in ZIP files too. Although it is kind of platform specific, I like the idea of using AWS API Gateway to pull resources on the fly from zipped archives and making the API methods look exactly like those native to CKAN. You can event pull tabular stuff into a temporary DB to recreate the methods used for updating records in a tabular resource before wrapping it all back up into a zip.