This topic gives an overview of the key libraries for managing Data Packages and sub-specifications such as Tabular Data Package and JSON Table Schema.
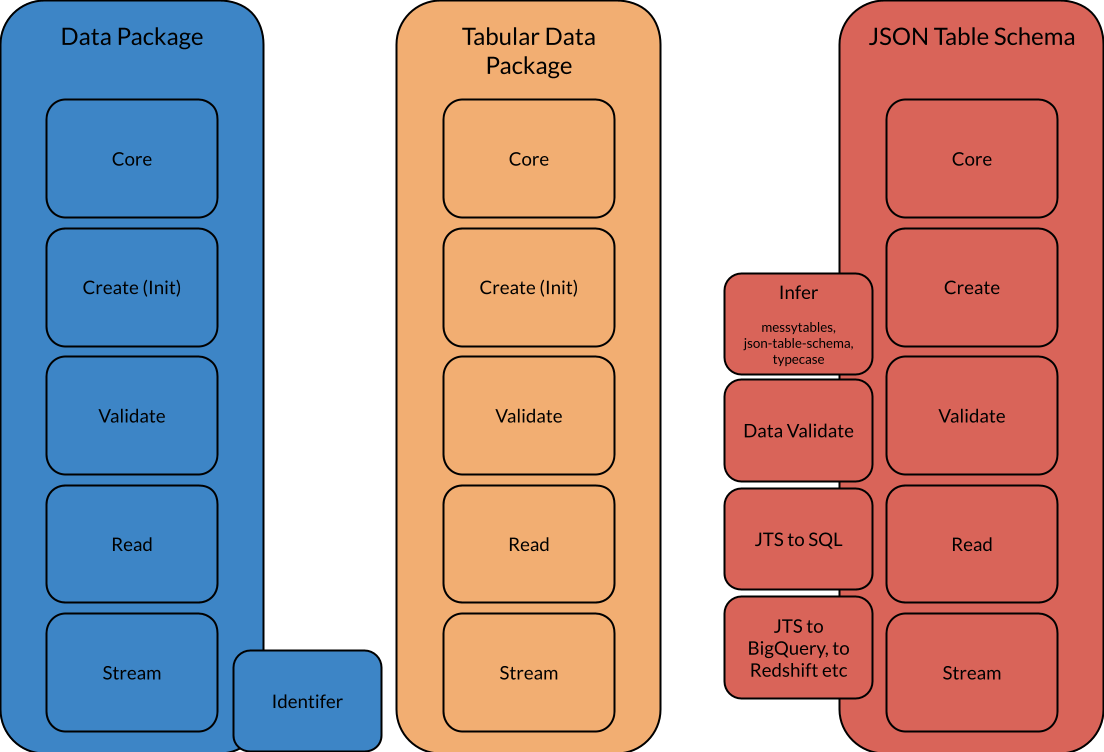
Crudely:
- For each specification the core operations are:
- Core - “modelling” the underlying JSON spec in a given language’s classes e.g. in Python having a “DataPackage” class etc
- Create / Init: creating new Data Packages (datapackage.json) and writing to disk
- Validate: check datapackage.json is valid (not about checking data)
- Read: load a Data Package (datapackage.json) from disk and normalizing it (this can be almost trivial but e.g. inlining READMEs is not plus it can encapsulate loading from remote urls)
- Stream: stream resources data (this is something that could be outside)
- Generally we would expect one library to provide all the core operations, or most of them in one. It is possible that they may be partially split out (as in node libraries) and then combined in one top level library (dpm)
- In addition there are a variety of other libraries - often, in fact, the most useful
- infer: infering a resource schema (json table schema for tabular data package) from the data
- data validation: checking data against a schema
- loading data into a given target backend e.g. sql
Status
Next step would be to produce a small spreadsheet with a matrix of these features and what existing language implementations there are (this would be a more detailed version of the current roadmap http://data.okfn.org/roadmap/)