One of the main goals of Frictionless Data is to improve the quality of data published and to make it easier to maintain this quality over time. Building on top of the excellent goodtables Python library we are launching a free service to provide Continuous Data Validation to everybody:
GoodTables.io builds on all the work that has been done in Frictionless Data specifications and tooling to date. It is designed to integrate with different backends and run validation jobs whenever data is updated. For this first Beta version, we are focusing on data hosted on GitHub repositories and Amazon S3 buckets.
There are a lot of rough edges to polish and you can see what issues are already on the roadmap on the issue tracker, we’d love to hear your early feedback and learn about your use of the service.
To register a new source simply login with GitHub and authorize the application. Once on the dashboard page, click on the “Manage Sources” link on the header:
For Github repos, click the Synchronize button to get a list of your repos, and then activate the relevant one.
For Amazon S3 buckets, enter the access key id and secret key, and the name of the bucket (we currently only support buckets located in the Oregon (us-west-2) region).
Validation jobs should start the next time a commit is pushed to the repo or a file is updated on the bucket.
Feel free to add any comments to this thread, your feedback is greatly appreciated!
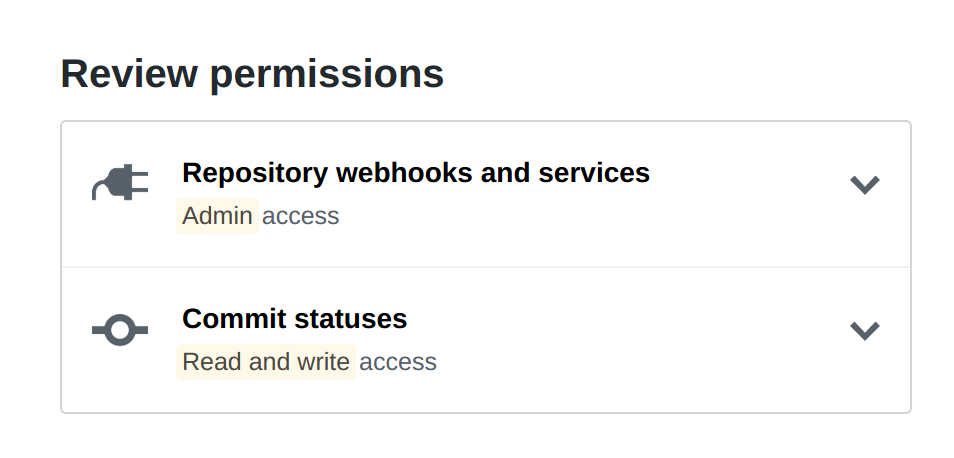
This is a really cool idea, and I’d love to set it up on our data repo, but the permissions required are really expansive - basically fully control of everything. That isn’t necessary for CI, we don’t provide those kinds of permission to Travis or AppVeyor, so I’m wondering why they are necessary here. Ah… looks like there’s an existing issue on this which I’ll go comment on.
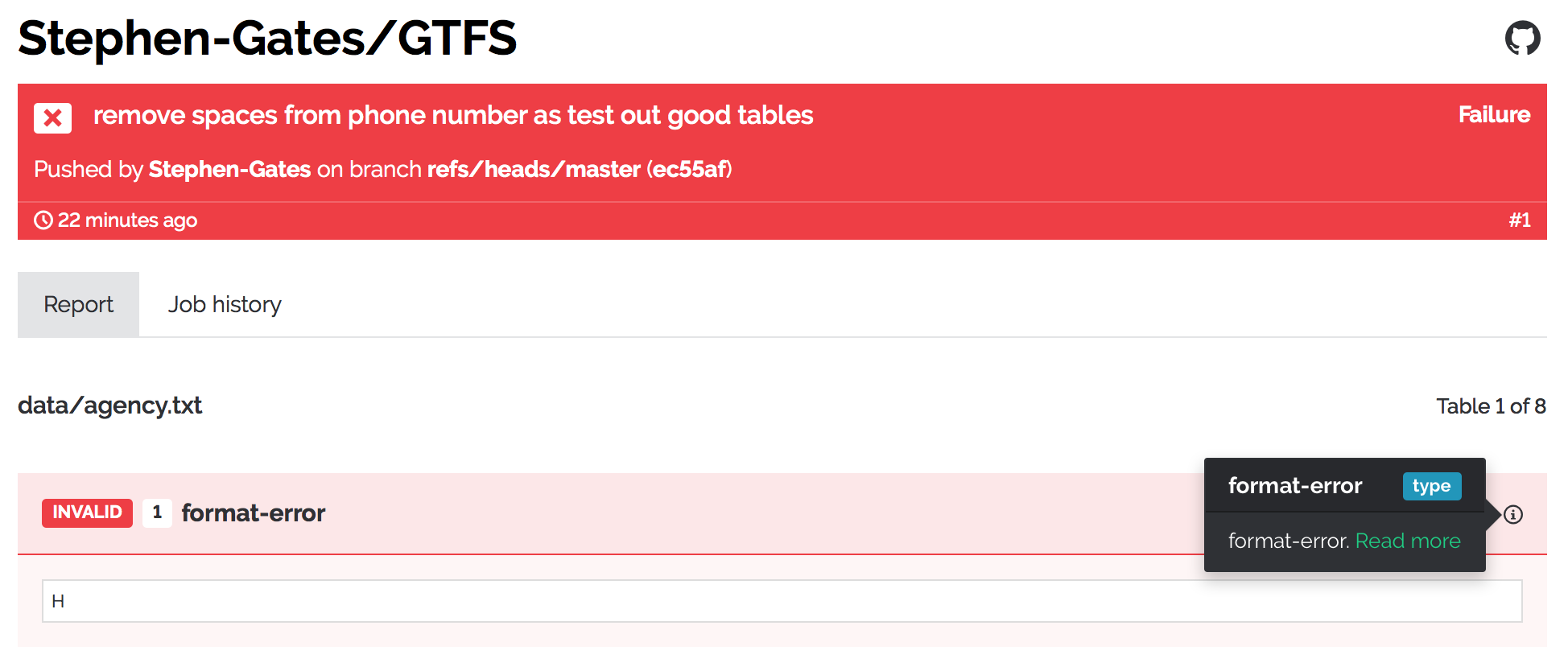
The error messages are definitely not very helpful in this case. I’m pretty sure files don’t need to have the .csv extension but I’m not sure what went wrong there. @roll any ideas?
@ethanwhite repos from the orgs you belong to should definitely come up so something is not right. We’ll investigate. Can you try and resync anyway to make sure it wasn’t a glitch?
Yes. For now we support only Tabular Data Packages. In specs-v1 will be introduced concept of Tabular Resources so support for general Data Packages will be added pretty soon.
Yep, that would help. As a thought from a complete newbie (sorry) to this area of things, is goodtables.io expected to just validate + report on the data (acceptable to me), or is it expecting to have write access and actively muck around with data directly?
From my point of view (a bit of a control freak about things changing my data ), I’m absolutely happy to run validation/checking processes on data which reports on them for manual follow-up/correction. Directly changing things itself though without oversight is a complete no go. At least, not without some kind of (extensive?) trial period to ensure there’s no edge case bugs which incorrectly change the data.
Asking that because the goodtables.io sign in for GitHub requests change level access to my repos. And that’s an absolute “not going to happen”.
I’m not aware of any other CI system that does this, though I’ve only used Jenkins and Travis CI in any depth so that could just be me.
@justinclift Right now the service should only ask for the following permissions:
repo:status: We need this to be able to write the commit statuses (success or failure)
admin:repo_hook: We need this to be able to create and remove the necessary webhooks to ping the service whenever there is a commit pushed to the repository.
These don’t allow the service write access to the actual contents of the repo, and if we ever need to do that it will require a separate authorization process by the user.
@amercader Spotted a minor bug in the sample report you pointed to.
In the hmmm… “commit heading” up top, there is this text:
Pushed by Adrià Mercader on branch refs/heads/master (7c765e)
There’s a link on the “Adrià Mercader” text going to https://github.com/Adrià%20Mercader instead of amercader (Adrià Mercader) · GitHub. At a guess the template for the commit header message is just inserting the wrong variable (user full name instead of GitHub account name). Should be pretty easy to fix.
Thanks, it’s probably just my knee jerk reaction of “Aaagh, it’s asking for more than just read-only!”. I’ll investigate the meanings of those permissions later (prob tomorrow), and think it over more then.