Hey everyone, hope this is the right place for this
As part of my master’s thesis I’m currently working on a small tool that can help people collect data.
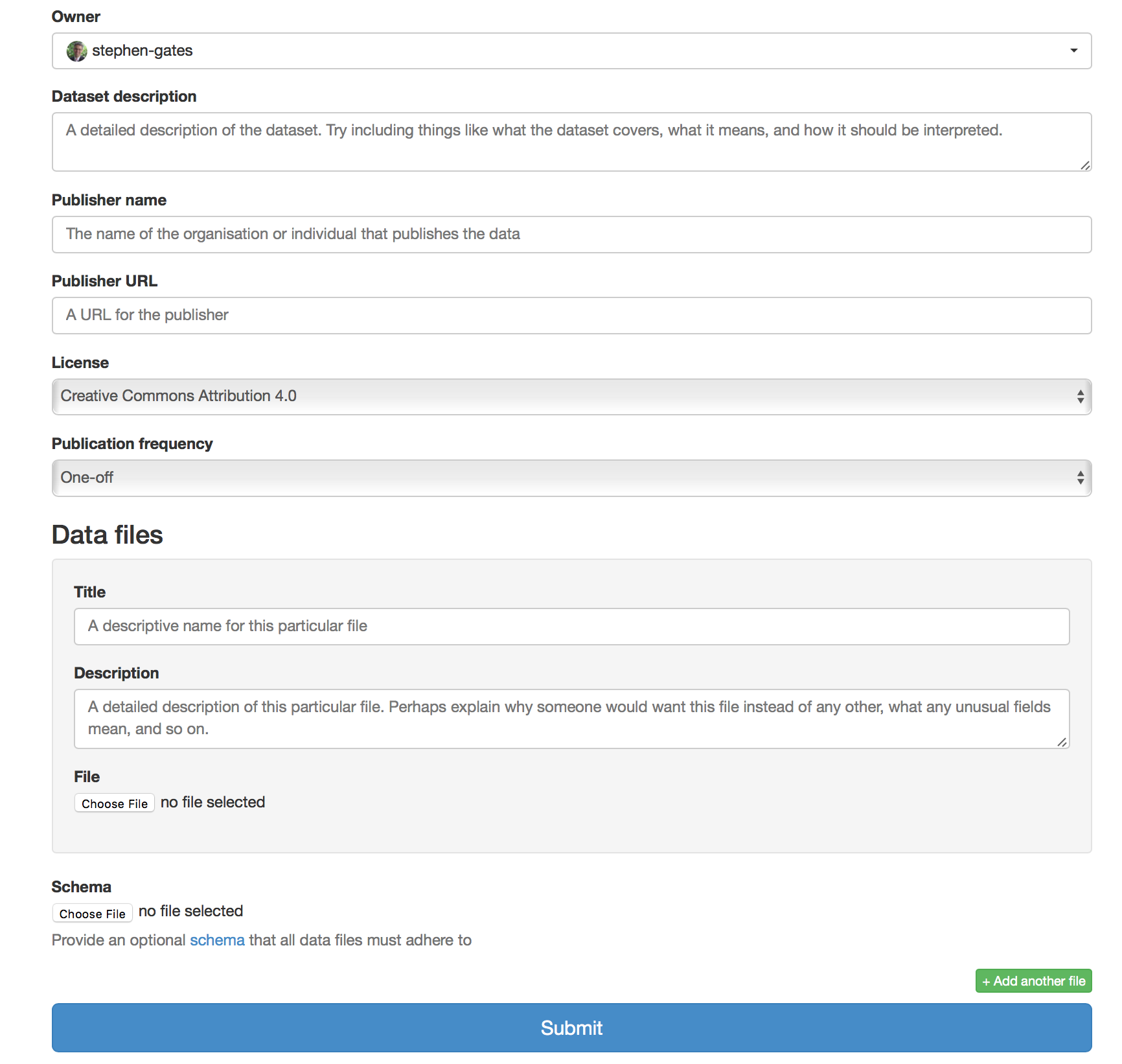
The main idea is to build datasets by simply creating a nice little form so everyone can help by adding and maintain the data.
You could say a GitHub for structured data - but usable for people without a computer science degree.
Some of the features that are working so far:
very simple form builder
basic rights management: add contributors, accept oder decline new or modified entries
REST-API
Some ideas what this could be used for:
create datasets of
The first pre-alpha version is now live and I’m looking for general feedback, ideas what the tool could be used for, your opinions on whether this even makes sense - anything! Just use this thread of hit me up on twitter @th_p - that would be awesome!
Keep in mind that this is very much a throw-away prototype with many rough edges and some fragile pieces. If people think it’s useful I’d very much like to rebuild it properly after I’m done with my thesis.
Thanks for your contribution! I actually moved this post to our Labs category. The description for the Labs category is very bad, so I will update it now, but Labs is exactly the kind of place to post this and other tools in development for working with open data.
There is a tool in the same spirit, that allows people to define their own data forms and is used in several community projects in Colombia, includings “data based campaigns”. The name is Tupale: https://tupale.co/.
Would be nice to have a more prominent link to the source code and to show technologies behind.
Hey, thanks for your reply!
Unfortunately I don’t speak spanish so I can’t really tell how that site works.
My project is not open source at the moment, that’s why there’s no link to any code.
Still, feel free to sign up and give it a try - really looking forward to some feedback regarding the workflow & freatures!
@Offray I will think about making it Open Source after being done with my masters thesis. I was looking for feedback to know if it even makes sense to put more effort into it now.
The doubt about putting more effort into it is a good reason to make it open source soon, so it can live beyond your particular research / time frame. I think we need more prototypes going beyond academia into the real world. Here is my attempt in that direction.
Making things open source is still a lot of work while non-technical people still can’t use it.
Not sure if anyone would look at the code if no one even signs up to give the tool a try…
Yes, there is a chicken and egg problem here. In my case, making my research objects open source from the beginning is a way to tell others that my interests go beyond my particular research, getting the data or writing my thesis and that I’ll try to improve things to make them usable outside my research, but that this is also an on-going open process where others are invited. People can become full participants to the extend of their interest instead of only “data sources” / informants for my particular research. We have a small community around my open research project and has taken more time that only invite them to surveys, but it is kind of working. We still have issues as with any young community, and my research has some ethnographical approach, so characterizing this broader participation and the issues with it, is also part of the research. May be this approach could help you.
I have set up a feedback form so I can evaluate whether there’s a need for such a tool. I’d be very happy for every submission - it would help me a lot! http://alpha.madata.io/20/add
Hi Thomas,
I think its going to be hard to tear me (and maybe other people too) away from CKAN. Although I appreciate that what you have in mind is something a bit different, and I think the general idea is great. In the “OK Labs” in Germany we constantly have the case that people try to assemble the data they want because its not readily available. But there again I wonder if GitHub is a better fit for these “messy” projects. Also in that case we can’t assume anything about the licensing of the data, so automatically assigning an open license would not work.
ANYWAY, I would nevertheless happily fill in the survey but am put off by the registration.
Thanks so much for your feedback, really appreciate it!
This tools aims to accompany other great tools like CKAN (which is great to publish but not really to collect data) or GitHub (which is awesome for developers but very hard to understand for non-technical people), not to replace any of these.
Regarding the license, there will definitely be a way to choose different flavors just like in CKAN, but like a lot of other features this wasn’t implemented yet as I’m running out of time to finish my thesis. But that’s exactly the kind of feedback I’m looking for!
Regarding the registration - I want to make sure people have at least tried the tool before filling out the survey form as there are some specific questions about to process of data collection and how to improve that.
If it helps - you can just use any throw-away (or even invalid) email address, since you won’t get activation (or any other) emails.
May I ask what chapter of the ‘OK Labs’ you’re in? I visited the Stuttgart chapter a few months ago.
I agree that GitHub is challenging for non-techies but it does have many strengths. The Octopub project has tried to take advantage of Github for data publishing (example published dataset). It creates a simple data package that includes a json table schema that can be optionally improved by the publisher to provide clear information about the structure of the data and could be used to validate the data.
Octopub only takes data contributions via Github issues or pull requests.
Where a tool like yours could contribute is by using the schema to create a data entry form based on the schema. The form could ensure the fields were the correct type, format and followed the constraints.
You could then extend the solution to simplify the process where the publisher would review then accept or reject the pull requests for the contributed data.
The tool currently uses JSON Schema to create these forms, with a nice visual builder so everyone can use it.
I’ll have to look into how that’s different from what the Frictionless Data Specification expects. I’d like to keep it a bit more flexible than just a table schema though.
The review process for accepting “pull requests” for data is already in place!
Hi Thomas,
I am involved in the Munich group. If you made it to Stuttgart, maybe you can visit us one day?
Now I finally tried out the tool and I agree it is meeting a need for collecting “rows” of a dataset (does the end data collected actually always look tabular or could you also collect a array of JSON objects?) from many people without them having to edit a file or a spreadsheet. I know of a project right now trying to do this and everyone has to make a copy of a JSON file, edit and submit. So, awesome!
@Stephen does GitHub’s CSV view allow editing in any visual or way that ensures coformance to data types? I don’t think so. That is indeed a place where this tool could help: give it a GitHub/Data package URL and it does the rest…
What I’m actually interested in (and what the aforementioned project is doing) is allowing people to create “datasets” even if they don’t have the actual data yet. I’d like to make this easier. This is a slightly different use case. Do you see a way to force a schema upon people for the actual dataset creation? The only available platform I know of for doing that is CKAN with the scheming extension.
Octopub does let you define a schema and validate data (see below) but does not provide a user interface to contribute a row of data. Based on @ThomasPe’s idea, I’ve added issue #195 to Octopub to suggest just that.
The data can take any form that JSON supports, including objects and arrays. This is currently only limited by the form builder which is currently being redone to include these features and also more validation options.
I’m actually on my way to Munich right now as that’s where my parents live there I’d be glad to meet up some day when I’m done with my thesis!
@kleper is the guy behind tupale, so he can give you better feedback on it. I’m working with Grafoscopio. Tupale is oriented towards defining and collecting data. Grafoscopio is oriented towards literate computing, reproducible research, data activism and visualization.